
NVIDIA's new H200 Tensor Core GPUs and TensorRT LLM updates tackle soaring AI demands today
The trend is clear - generative AI model sizes are ballooning. Blackwell won't be here anytime soon, but Hopper GPUs with new memory and TensorRT advances will save the day.
#genAI #generativeAI #ai #nvidia #hopper #h100 #h200 ##DataCenter #LLM


NVIDIA Hopper GPUs supercharged with HBM3e, currently the world's fastest memory. (Image source: NVIDIA)
As the demand for increasingly sophisticated generative AI models continues to develop, so too are model sizes, which are getting larger. Clearly, this will be a problem for infrastructure service providers whose customers rely on their hardware solutions to train new models and deploy them effectively.
To address the growing need for inference platforms today, NVIDIA is announcing that its new H200 Tensor Core GPUs are sampling to customers today and will be available from all the usual OEMs and ODMs in the data server industry in Q2 2024 – which is just days away.
To recap, the H200 is essentially an H100 Hopper GPU but is now endowed with speedier and higher capacity HBM3e memory over the original H100 GPU configuration using HBM3.
The result is a massive boost in memory capacity per GPU of 141GB per GPU (up from 80GB), with a total memory bandwidth of 4.8TB/s (up from just over 3TB/s). Tested on the latest MLPerf Inference benchmark, which is developed by a consortium of AI leaders across academia, research and industries to provide an unbiased evaluation of training and inference performance of hardware, software and services, the miracle of an updated memory technology is a massive boon to inference performance as illustrated in the image above/below. The latest benchmark version incorporates even newer tests and workloads, such as the updated Llama2 language model with 70 billion parameters to better represent the evolving inferencing needs.

A 45% performance uplift over NVIDIA H100 in MLPerf's Llama 2 70B-parameter benchmark.
Setting new machine language performance records with over 31,000 tokens/s on the MLPerf Llama 2 benchmark, the NVIDIA H200 Tensor Core GPUs are just what’s needed at this point in time. More so, the H200 is drop-in compatible with the H100 (similar physical connections and TDP requirements), so existing customers can switch them out without a penalty in power requirements for a big boost in inferencing performance. Consequently, the GH200 Grace Hopper superchip (further chip details here) also benefits from this update with the same upswing in memory throughput to tackle these ever-growing workloads expeditiously.
Why do we need such powerful accelerators?

(Image source: NVIDIA)
As the demand for increasingly sophisticated generative AI models continues to develop, so too are model sizes, which are getting larger. Back when the transformer deep learning models were new and unlocked notable performance in self-supervised learning through natural language processing (NLP) for summarisation, translation, and computer vision, Google’s BERT-Large large language model (LLM) was one of the most prominently used. That was roughly 340 million parameters in size. Today, the largest model size is at a staggering 1.8 trillion parameters, and according to the trend line, it’s not going to stop.
While NVIDIA’s newly announced Blackwell GPU and platform at GTC 20204 are designed to tackle trillion-parameter-sized generative AI models in real-time, they will not be available to customers until at least the end of 2024 or even early 2025.
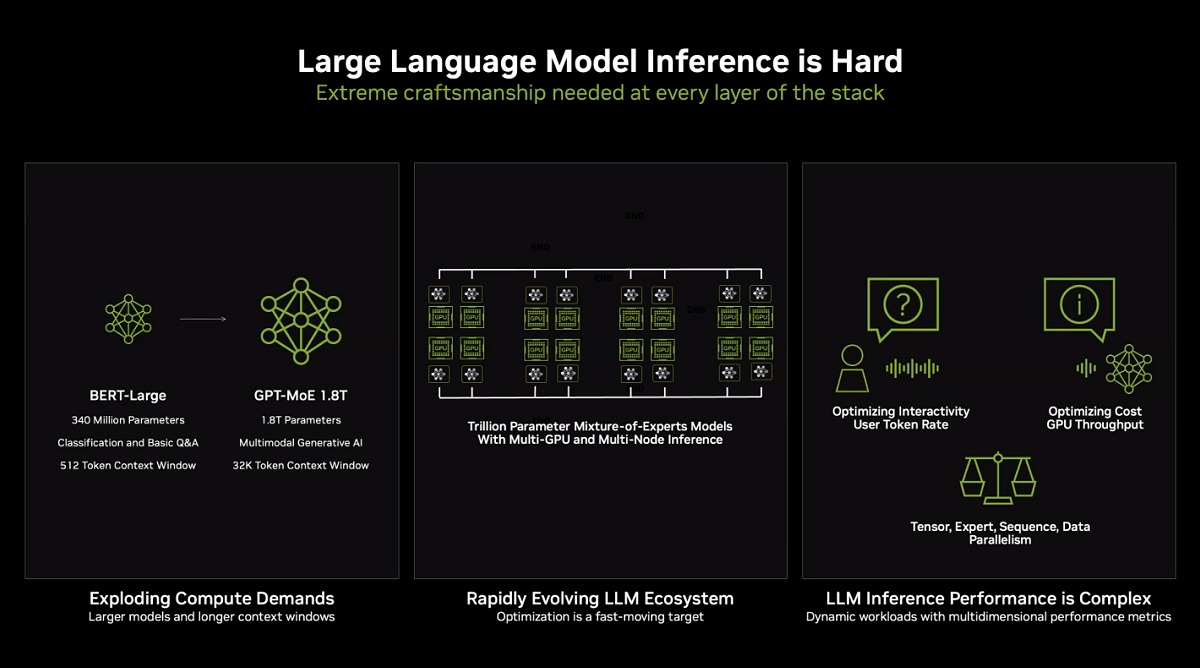
Click to view more details. (Image source: NVIDIA)
For now, the Hopper architecture, GPUs and Grace superchips will be the highest performing set of offerings from NVIDIA.
Why are inferencing platforms in high demand?

Click to view more details. (Image source: NVIDIA)
NVIDIA has shared that approximately 40% of their data centre revenue can be attributed to inferencing platform needs. This underscores the market demands for inference training across various domains such as LLMs for textual manipulation, visual content generation and recommender systems. The latter’s model size can be exceptionally large in order to be make its mark accurately in fruitful and timely recommendations.
The magic of NVIDIA’s TensorRT-LLM advances
To recap, to better utilize the Tensor Cores present within these modern GPUs that are responsible for AI processing tasks and workloads, TensorRT-LLM was developed as an open-source library to accelerate and optimise inference performance on the latest LLMs run on NVIDIA Tensor Core-equipped GPUs. First released in September 2023, it has already doubled the inference performance without TensorRT-LLM. Thankfully, NVIDIA continuously improves the inference compiler that works with NVIDIA GPUs and has improved TensorRT-LLM by continuously incorporating newer models/features/functions and thus has more performance gains to show.
Here are some ways TensorRT-LLM accelerates processing LLMs in a generative manner:-
- Optimise GPU utilisation through in-flight sequence batching of instructions
- Higher GPU memory utilisation through better KV Cache management
- Multi-GPU and Multi-Node deployment and management is increasingly important to improve inferencing performance. This LLM helps manage this.
- Fitting larger models and increasing performance via FP8 quantization
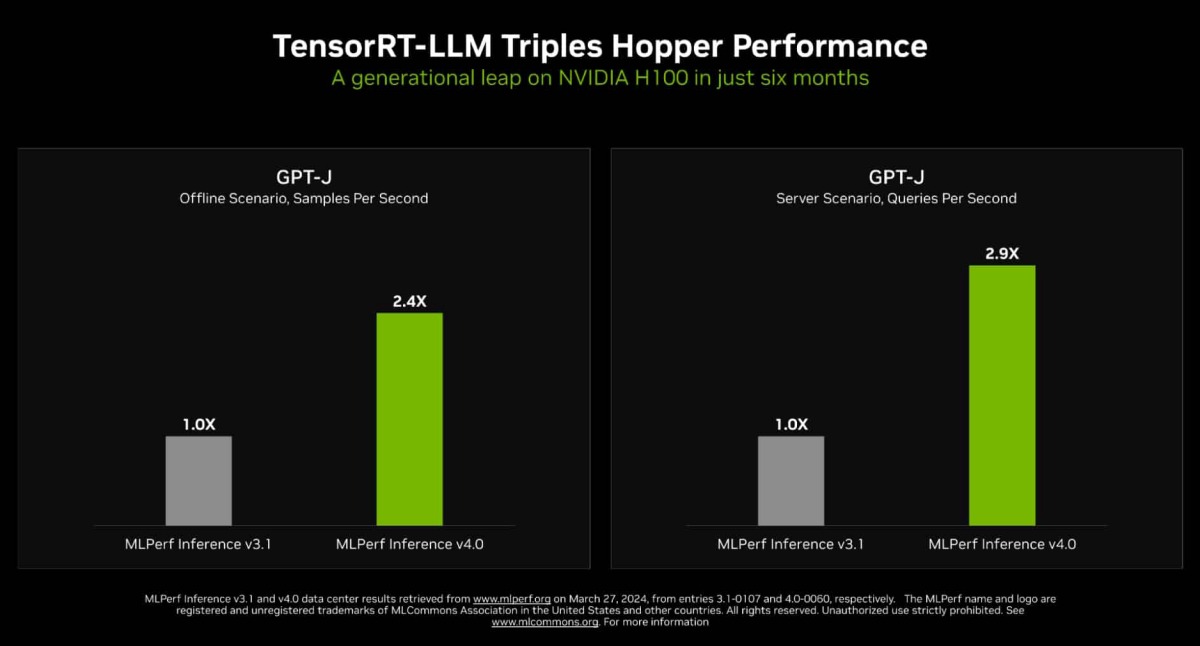
Click to view more details. (Image source: NVIDIA)
In just six months since of its release, TensorRT-LLM now triples the performance of NVIDIA Hopper GPUs (while tested with GPT-J model). This means H100 and H200 GPUs are much more capable than they already are on their own, potentially delivering massive uplifts (subject to tests and models used) while running on the same hardware. This goes a long way in cementing NVIDIA as not only a hardware platform leader, but because of its relentless updates by its software engineers, it is a platform that its customers can count on to get even more value out of their investment and push the needle further in delivering the inferencing performance needed in this fast-evolving scene.
Soure: NVIDIA
Our articles may contain affiliate links. If you buy through these links, we may earn a small commission.