
NVIDIA’s new 200-billion transistor Blackwell B200 GPU will tackle XXXL-sized generative AI models
With a focus on accelerated computing, breakthrough data processing, and tackling trillion-parameter generative AI models, Blackwell is huge, both physically and in its promise for another way of change. #nvidia #blackwellgpu #gtc2024 #b200
Note: This feature was first published on 19 March 2024.

NVIDIA Blackwell Architecture Image; click to zoom in. (Image source: NVIDIA)
Powering the new industrial revolution
The internet has been rife with Blackwell GPU release rumours for many months now, but most are postulating what the GeForce RTX 4090 successor could offer. While that’s not focus of today’s launch, the Blackwell GPU architecture has finally been announced at NVIDIA’s premier AI conference, GTC 2024. With a headline such as wielding power to drive the new industrial revolution, the Blackwell GPU is shaping up to be a key enabler for accelerated computing, breakthrough data processing, engineering simulation, drug design, quantum computing, and generative AI in a very big way.
After all, NVIDIA promised to solve data centre woes, and that it did with the Ampere-architecture-based A100 superchip in 2019. By 2022, NVIDIA’s focus was crystal clear to advance AI in a meaningful way to drive the world’s AI infrastructure, and that they did with the H100 Hopper architecture superchip. What better example than Generative AI and large language model (LLM) processing, both of which came into existence by training on and being powered by NVIDIA’s hardware? Today, you can’t escape a day without hearing, using, or seeing the fruits of generative AI and being the “defining technology of our time”, as heralded by none other than Jensen Huang, founder and CEO of NVIDIA. It’s little wonder why this billionaire’s personal wealth index has risen tremendously in recent times while his company’s stock prices are at their highest in its history.
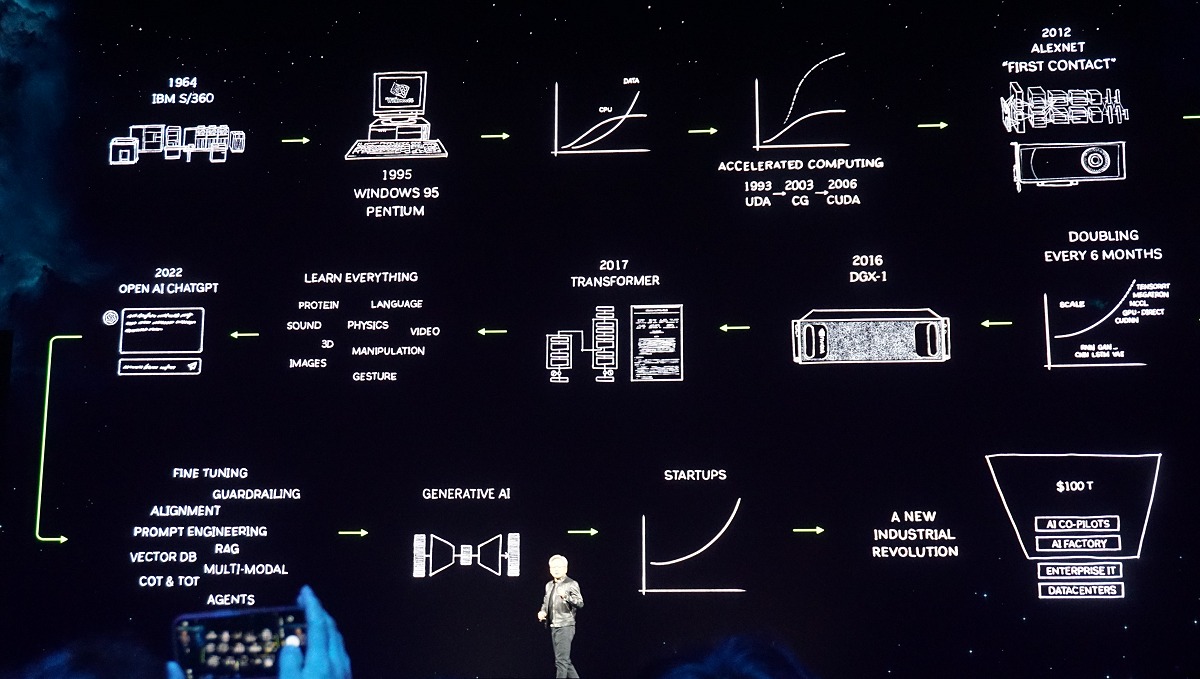
A brief look at NVIDIA's rise beyond the gaming world and its path towards enabling the new industrial revolution.
The Blackwell GPU architecture is riding on the back of the high praise achieved by the prior Hopper architecture. It boasts some insane top-line stats such as up to 30x inferencing performance, 4x in training performance, and an impressive 25x reduction in energy consumption and operating cost for LLM inferencing coupled with a new compiler. Boasting over 200 billion transistors, the NVIDIA B200 Blackwell processor boasts numerous breakthroughs to bring about these insane figures.
Named in honour of David Harold Blackwell — a mathematician specialising in game theory and statistics, and the first Black scholar inducted into the National Academy of Sciences — the new architecture succeeds the Hopper architecture, launched just two years ago.
With a huge promise to fulfil, these are the six ‘miracles’ or breakthroughs that have made the NVIDIA B200 Blackwell processor a reality:-
1) World’s most powerful chip

Click to view a larger image. (Source: NVIDIA)
Boasting a whopping 208-billion transistors, the Blackwell GPU in in fact composed of two of the largest dies possible from TSMC and are unified together as one GPU. If you notice the size of past dies for NVIDIA’s super chips, you’ll get an idea of the largest die size possible from TSMC. Manufactured on a customized 4NP TSMC process designed for accelerated compute needs, these two dies are connected by a 10TB/second chip-to-chip link to operate as a unified, single GPU. That fabric interconnect alone could rank as a separate miracle.
Supporting 192GB of HBM3 (a big jump over the H100’s 80GB), and a combined memory bandwidth of 8TB/s (up from 3TB/s), the massive jump in memory bandwidth is certainly beneficial to match the chip’s overall throughput capabilities.
2) Second-Gen Transformer Engine

To recap, NVIDA first introduced a Transformer engine in the Hopper architecture to specifically target deep-learning models that enable self-supervised learning and have enabled natural language processing, text summaries and computer vision in a big way. As you can figure out by now, these are the core areas of use for generative AI today. We’ve covered this in more detail here. In Blackwell’s GPU, NVIDIA expanded the Transformer engine’s capabilities by adding more processing formats like FP4 and FP6 AI inferencing, which will help evolve the model complexity and thus uplift processing efficiency or tackle even larger model sizes.
3) Fifth-gen NVLink

(Image source: NVIDIA)
As powerful as a single B200 Blackwell GPU is, NVIDIA's scalable GPU architecture via its proprietary NVLink high bandwidth, energy-efficient, low latency, lossless GPU-to-GPU interconnect is a crucial enabler in massive multi-node computational performance, and this has been growing nicely in every generation in both throughput and fan-out capability.
The latest fifth-generation NVLink boasts 1.8TB/s bidirectional bandwidth per link and scales out further at up to 576 GPUs (this is twice the limit of the H100) per NVLink domain. To support that many GPUs interconnected, this requires a next-gen NVSwitch, which also supports 1.8TB/s NVLink speeds. It’s so complex, that it alone has 3.6 TFLOPS of in-network computing to help offload some neural network operations.
4) RAS Engine
The B200 Blackwell GPU has a built-in RAS engine so that data centers built even at the largest scale, can constantly monitor its health 24/7. A common acronym in the enterprise world, RAS refers to reliability, availability, and serviceability. With a built-in self-test engine, this maximizes system uptime and improves resiliency as the scale-out deployment size is increasing tremendously gen-on-gen.
5) Secure AI
While the Hopper architecture debuted Confidential Computing support, Blackwell architecture takes this further with support for new native encryption protocols. Privacy-sensitive industries like healthcare and financial services deploying Blackwell processors will appreciate this.
6) Decompression Engine
As data processing increasingly becomes GPU-accelerated, companies would want to extract the highest performance out of data analytics processing. With a dedicated 800GB/s high-speed decompression engine onboard supporting the latest compressed data formats, the Blackwell GPU can operate on compressed data formats without waiting for the CPU to first perform the decompression task.
Scaling up the Blackwell architecture and introducing a new rack-scale unit of compute
Remember Grace Hopper superchip? You can now get a GB200 Grace Blackwell Superchip that connects two B200 GPUs and the NVIDIA Grace arm CPU over a 900GB/s NVLink chip-to-chip (C2C) interconnect. While Blackwell can use faster NVLink transmission speeds, the Grace CPU doesn’t yet support that speed and will use the last generation’s transmission standard.

(Image source: NVIDIA)
But it doesn’t end there. The GB200 is a prime component for NVIDIA’s new multi-node, liquid-cooled, rack-scale NVLink system for highly compute-intensive workloads. 72 Blackwell GPUs and 36 Grace CPUs are fully interconnected over an NVLink Switch Rack backbone. Dubbed the NVIDIA GB200 NVL72, it also sports NVDIA Bluefield 3 DPUs to offer cloud network acceleration, zero-trust security, and GPU compute elasticity in a flexible and scalable AI cloud system.

(Image source: NVIDIA)
The GB200 NVL72 boasts a 30x performance uplift over the same number of H100 GPUs in LLM inference workloads, while also reducing running costs and energy consumption due to Blackwell’s sheer performance uplift. The platform also acts as a ‘single GPU’ with 1.4 exaflops of AI performance and a combined 30TB of memory for the next-gen building block of a DGX SuperPOD.

(Image source: NVIDIA)
On the other end of the scale, there’s also a HGX B200 server board that can link up to eight B200 GPUs with an x86-based generative AI platform. A more compact supercomputer variant of that would be the DGX B200 offering a scalable air-cooled design. For reference, its past incarnations are the DGX H100, and the DGX A100 personal supercomputer.
Blackwell is also available soon via Cloud Computing partners

(Image source: NVIDIA)
The GB200 superchip node will be heading to NVIDIA’s DGX Cloud, and will also be heading to cloud infrastructure partners like AWS, Google Cloud, Microsoft Azure and Oracle infrastructure to offer Blackwell-powered compute instances.
Read Next
1) Blackwell GPU power onboard NVIDIA Drive Thor will unleash Gen AI experiences in your upcoming car
2) NVIDIA is embarking on a project to support humanoid robot development
Our articles may contain affiliate links. If you buy through these links, we may earn a small commission.